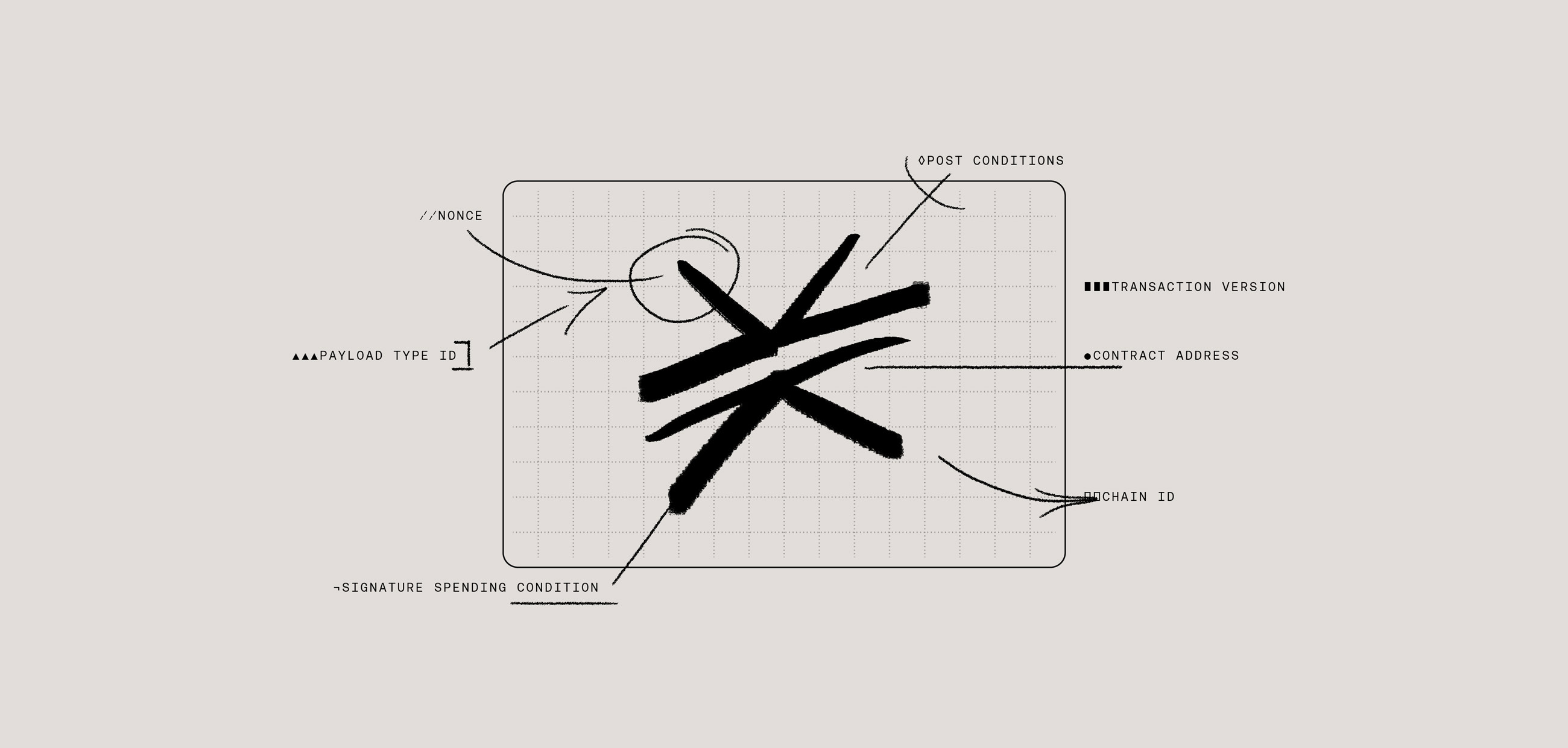
Contents
As part of the Infrastructure Series, this post is intended to provide some context to the posts yet to come. It may help explain why we’ve made certain decisions for our infrastructure to those new to this space, while re-aligning some of Hiro’s priorities with infra-veterans. After reading this post, you’ll have a better understanding why infrastructure is important to us, why we think it should be important to everyone hosting software, and some hard lessons we’ve learned — or had to watch others learn — in the past.
¯\_(ツ)_/¯ Why Should I Care?
Since its launch in January, the public services Hiro hosts for the Stacks ecosystem are already being used by tens of thousands of users around the world to do things like develop dapps, stack STX, deploy Clarity smart contracts, bootstrap stacks-nodes, serve the explorer, the desktop and web wallets, and so much more. It’s important that these open-source services, regardless of who hosts them, are backed by infrastructure designed to scale and keep the metaphorical ship sailing at full speed ahead even when the digital waves are choppy. Let me explain why.
As software developers and engineers, it’s usually counterintuitive to spend heaps of time and stacks of money on a project to ultimately have it crash, get hacked, or provide a frustratingly slow experience (unless you like watching the world burn 🔥)
Good design principles for infrastructure is a skill learned over time just like it is for programming, albeit sometimes with more hindsight involved. And the further down the rabbit hole you go with shaky infrastructure, the harder it’ll be to dig yourself out as traffic grows and people start depending more on your public Stacks API, where any downtime will be amplified amongst your users.
It pays dividends to use industry best practices early-on, avoiding the need for potentially months of rework and calls in the middle of the night. To ensure a service is given the opportunity to reach its maximum potential and usefulness, one should strive for well thought-out infrastructure, ideally before said service is live. When done right, an efficient yet effective design will end up saving you time and money, while enabling your public nodes or Stacks services to work their magic.
🕳️ Common Pitfalls
That being said, there is no one-size-fits-all solution for everyone; some may not have the same options compared to others due to constraints like time, money, or resources. Running Stacks services in the cloud won’t be for everyone, some may prefer physical, bare-metal servers. It’s important to understand some common pitfalls to avoid analysis paralysis and effectively cater to your specific needs.
Don’t over-engineer a solution to a simple problem
It’s easy to succumb to scope-creep and lose track of what’s actually needed when addressing slow performance of a Stacks node, high latency for the explorer, or scaling challenges for the API. While it’s undoubtedly cool to watch your services scale up to 5000 instances and fail-over to 10 different regions at the push of a button or in response to an event, the cost vs benefit tends to wane and use cases get more specific as solution complexity rises. Be sure to understand the end-goal version of a solution you’d like to implement and break it out into smaller consumable pieces before starting on it.

Giving a service more resources isn’t always the answer
Especially today where many apps are designed as microservices instead of monolithic beasts of Ye Olde Tymes, you can’t always just scale up a VM, giving it more memory or processing power, and expect a better result in return. Scaling out by adding more running instances of that app is often more effective for many modern services like the Stacks node, and should be considered just as equally as scaling up depending on the metrics of your deployment.
Convention over configuration
If the defaults are appropriate for your use-case and expectations, use them! While it's nice to be able to call it your own, if you plan on running or hosting Stacks services, it can quickly turn a simple deployment complex by over-customizing your infrastructure and services beyond what's necessary.
The stacks-blockchain software has some example config files for launching a stacks-node, where many options are set to sensible defaults for the majority of users. Similarly with the stacks-blockchain-api, there are plenty of options than can be set via environment variables. However, if you aren't exposing it to the public and don't expect high traffic, you probably don't need to configure caching for it. We suggest first understanding if these default settings will work for you before deciding to add customizations.
Don't become another statistic of cyber attacks
It's easy to overlook security. Implementing security measures for services deployed often becomes an afterthought for many as it requires deliberate action and consideration. Ranging from network firewalls, authentication, authorization, and generally expecting the unexpected, there's plenty of different aspects to consider.

Making time for these considerations when deploying your own Stacks services is important and necessary. Leaving extraneous ports exposed to the public for any service is an open invitation to armies of bot crawlers and bad actors on the internet to poke for holes, try to take your service down, or look for a way in. At Hiro, we find these kind of attempts occurring every day at some level. If not adequately protected, this could expose sensitive configurations of your environment, cause excess downtime, risk sharing personal details, or worse, make everyone laugh at you. And you don't want to be laughed at, probably.
We'll be sure to point out areas requiring extra attention to these security details in upcoming posts.
Throwing more money on the fire won’t always put it out
When you have a hammer, everything looks like a nail. The same goes for high budget ceilings, but sometimes it doesn’t matter how much money you throw at a problem. While improving security, resilience, and availability will help with a majority of the challenges you may face running your own public Stacks software, novel edge-cases are being found every month as new features and smart-contracts are deployed. Sometimes the best solution to an infrastructure problem doesn’t reside in its configuration at all, but rather expanding the service’s capabilities to handle new problem paths differently.
If you encounter such unexpected errors or bugs in any Stacks software, feel free to ask the Discord community for help, leave a post in the Stacks forum, submit an issue in the appropriate repository — or better yet, a pull request!

Albeit only a fragment, it's not possible to encapsulate all of the context and forethought that goes into designing infrastructure and the challenges of hosting services publicly in a single post. However, the content above should help explain for future posts why we've made certain decisions for our infrastructure, improvements we're working on, and why you may (or may not) want to do the same. While it may only be a snippet of what you'll discover on your own, we'll be sure to cover more specific scenarios we've experienced first-hand in the following posts of this Infrastructure Series.
In the next post, we'll be getting more technical on how we've designed the infrastructure which runs the public Stacks software at Hiro! We'll be covering topics on cloud providers, auto-scaling, networking, Gaia storage, security, infrastructure automation, and more.